ls svm pso 基于PSO-SVM的油田注水动态预测模型
对油田注水开发过程中的产油量、产水量的预测预报研究一直引起人们的极大重视,但由于油田系统本身的复杂性和多因素影响性等特点,给油田注水动态的分析和预测带来极大的困难[1]。目前,油田注水动态的分析和预测方法可以分为两类[2-4],一是传统经验统计模型,即在系统机理不完全清楚的条件下,由经验统计所建立的模型,如早期应用较多的是多元回归法、人工神经网络法;二是机理型模型,即根据油藏系统变化的特征建立物理模型,再根据物理模型的变化规律,研究实际油藏的变化,该方法是在系统机理完全清楚的条件下所建立的一种确定性模型。上述传统的经验统计模型只有在样本数量趋于无穷大时才能有理论上的保证,在实际的效果预测中样本数目通常是有限的,甚至是小样本,此时难以描述产油量与各种注水开发影响因素之间的复杂非线性,预测的相对误差通常在5%-10%;而机理型模型的建立需有准确的地层参数作基础,但这些参数的获取往往是在注水油田开发后期,导致其现实应用具有一定的局限性。 支持向量机(SVM)是近年来发展的一种机器学习算法,与传统的多元回归法、神经网络法相比,根据结构风险最小化原则,最大程度地提高其泛化能力,不过分地依赖样本的数量和质量,从理论上得到的将是全局最优解,克服了传统经验统计模型样本容量大、易陷入局部极小值等问题。因此,本文提出将SVM与粒子群算法(PSO)相结合,充分利用SVM在处理小样本回归问题上具有的独特优越性及PSO全局搜索优化等特点,考虑影响注水开发油田产油量的多项因素,建立了一种基于PSO-SVM的油田注水动态预测模型。 1 支持向量机回归原理 对于训练样本集,为输入变量,yi∈R为输出值,l和n分别为样本的维数和个数。SVM回归的目标就是要寻求某一函数f(x),使之通过训练,对于样本之外的x,利用f(x)能预测对应的y[5]。对线性问题,通过对目标函数的极小化确定回归函数,即: (1) 式中:常数C>0表示了对超出误差ε的样本的惩罚程度;ε为不敏感损失函数;、>0为松弛因子。将上述优化问题转化为对应的对偶问题: (2) 式中,,为待求的l维支持向量。 从而得到SVM回归模型: (3) 对于非线性问题,通过非线性映射x→Ф(x)将原问题投影至某一高维特征空间中的线性问题上进行求解。因此,非线性问题的SVM回归方程为: (4) X1 /万吨X2 /口X3 /口X4 /口X4X5Y /万吨 254.9310247691.15.6355.12 255.3126266721.16.3855.6 296.119285691.38.355.27 299.469295691.2911.956.04 295.2219305711.5316.4763.31 313.19306691.521.5974.36 314.3725331711.0118.1873.64 340.531349691.7116.180.04 320.0624368851.4912.9573.33 313.1320382981.348.1666.2 334.4412961281.147.6964.21 366.99214081301.1312.0957.99 340.25144221331.068.6553.35 224.7712242811.004.3151.34 式中:为核函数,可取RBF核函数,即,σ为核参数。 1.2 基于PSO的SVM参数优化 SVM的正则化参数C和核参数σ对模型的学习、推广能力影响非常大,一般采用网格搜索法或经验法,但网格搜索法的计算量较大,而经验确定法需要有较深厚的SVM理论基础。粒子群算法(PSO)为一种进化算法[1],可应用于遗传算法能应用的一切场合,其基本思想是首先初始化一群随机粒子,然后通过迭代找到最优解。其具体步骤如下: (1) 将样本分为学习集和测试集;(2) 给定最大迭代次数,最大、最小加权因子,随机产生n个粒子,每个粒子分别代表SVM的参数C和σ;(3) 根据当前参数C和σ,计算适应值;(4) 记忆个体与群体所对应的最佳适应值的位置;(5) 更新粒子的位置、速度,搜寻更优的C和σ;(6) 重复步骤3直到达到最大的迭代次数;(7) 利用训练好的SVM对测试样本进行预测。 2基于PSO-SVM的油田注水动态预测 油田注水开发过程中的指标分为状态变量和控制变量,状态变量是指油田注水开发过程中的年产油量(Y),控制变量是指影响油田注水开发年产油量的6个因素:注水量(X1)、新井投产数(X2)、生产井数(X3)、注水井数(X4)、年采油速度(X5)、措施增产(X6)。以上述6个影响注水油田年产油量的因素作为PSO-SVM预测模型的判别因子,而年产量作为模型的输出,基于某个油田的历史实测数据(表1),选取其中前13个样本数据进行训练,其余1个样本数据作为测试样本进行检验,并对样本数据进行归一化处理,建立油田注水动态预测的PSO-SVM模型。 设定σ、c的取值范围为:σ∈(0,1000),c∈(0,100);设置粒子群规模为20,粒子向量维数为2,迭代次数为50,通过计算得到最佳参数对(σ,c)=(435,0.53)。根据学习好的油田注水动态预测的PSO-SVM模型对1个待判样本进行预测,得到的年产油量值为52万吨,与实际产油量的误差为1.3%,证明PSO-SVM模型用于油田注水动态预测是完全可行和有效的。 表1 学习和测试样本数据 3 结论 (1) 结合PSO和SVM,提出了能广泛应用于油田注水动态预测的PSO-SVM模型。 (2) PSO-SVM模型充分利用了SVM在处理小样本学习问题上具有的优越性,能较好的描述注水开发油田的产油量与6个影响因素之间的非线性关系;而PSO卓越的全局并行搜索优化确保了PSO-SVM中参数的准确性。 (3) 将PSO-SVM模型运用于实际工程,结果表明,该模型的预测精度高,误差为1.3%。PSO-SVM模型是建立在已有的油田注水动态的特征规律学习基础上,不同油田应根据实际情况选择样本才能获得较可靠的预测结果。 参考文献 [1] 张瑞杰,常玉连,杨剑天等.某油田注水系统分压及优化节能技术[J].油气田地面工程, .2011.02
更多阅读
百度技术沙龙:基于大数据的预测技术
点击标题下「大数据文摘」可快捷关注本次分享的话题分别是“大数据与预测”和“基于互联网数据的社会经济预测”。回复“百度沙龙”,可一并下载2篇PPT在由@百度主办、@InfoQ负责策划组织和实施的第53期百度技术沙龙活动上,来自百度研
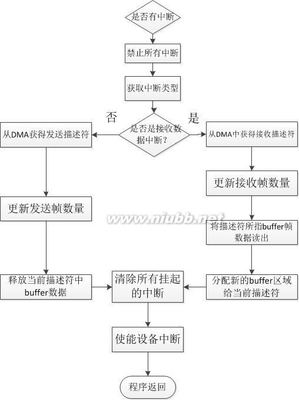
基于嵌入式Linux的千兆以太网卡驱动程序设计及测试 以太网卡驱动
基于嵌入式Linux的千兆以太网卡驱动程序设计及测试一.引言千兆以太网是一种具有高带宽和高响应的新网络技术,相关协议遵循IEEE802.3规范标准。采用和10M以太网相似的帧格式、网络协议和布线系统,基于光纤和短距离同轴电缆的物理层介
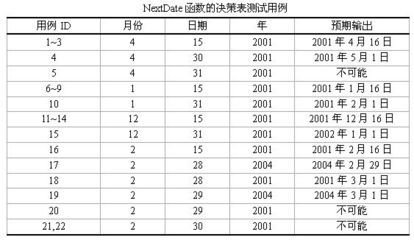
软件测试(14)--黑盒测试案例设计技术--基于决策表的测试 黑盒测试和白盒测试
决策表,也叫判定表。在所有的功能性测试方法中,基于决策表的测试方法被认为是最严格的,因为决策表具有逻辑严格性。人们使用两种密切关联的方法:因果图法和决策表格法。与决策表相比,这两种方法使用起来更麻烦,并且全冗余。决策表是分析和

EXAM终极面试影评-基于HR视角的解析 终极人鱼岛影评
终极面试影评-基于HR视角的解析 作者:六http://user.qzone.qq.com/269572946/infocenter 测试前言:…………(省略),在这间房子里,只有我们的法则,唯一的规则就是我们的规则,你们面前有一个问题,并且需要一个答案,如果你们试图向我或者
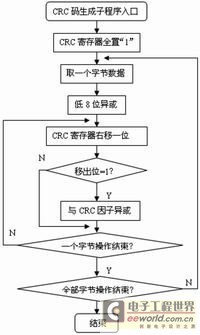
基于Modbus协议的串口通讯程序——(RS485总线系统应用之3) rs485 modbus协议
《基于Modbus协议的串口通讯程序》 东风汽车有限公司计量测试中心 王德宪内容摘要:本文在遵循Modbus协议的基础上,阐述了Modbus的两种传输模式和串口通讯程序的设计实例,并给出了VB语言的程序清单。可供有关技术人员在相关设计和应用