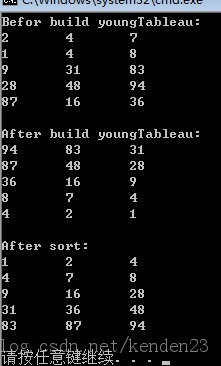
最后,给大家推荐我在网上看到的写的不错的几篇堆排序文章:
1.http://blog.csdn.net/super_chris/archive/2009/09/22/4581900.aspx
这一篇讲得很细致。
2.http://blog.csdn.net/made_in_chn/archive/2010/04/12/5473871.aspx
大家可以看看文章里的图,注意那是最小堆实现的图。
3.http://blog.csdn.net/midgard/archive/2009/04/14/4070074.aspx
同样讲的很细致的一篇。
4.http://student.zjzk.cn/course_ware/data_structure/web/paixu/paixu8.4.2.2.htm
这是网站很给力,有flash模拟堆排序,大家可以实际去看看。
1.原地排序就是指不申请多余的空间来进行的排序,就是在原来的排序数据中比较和交换的排序。例如快速排序,堆排序等都是原地排序,合并排序,计数排序等不是原地排序。排序稳定就是指:如果两个数相同,对他们进行的排序结果为他们的相对顺序不变。2堆的定义:
n个关键字序列Kl,K2,…,Kn称为堆,当且仅当该序列满足如下性质(简称为堆性质):
(1)ki<=k(2i+1)且ki<=k(2i+2)(1≤i≤n),当然,这是小根堆,大根堆则换成>=号。//ki相当于二叉树的非叶结点,K2i则是左孩子,k2i+1是右孩子
若将此序列所存储的向量R[1..n]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:
树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
堆排序:
堆排序是一种选择排序。是不稳定的排序方法。时间复杂度为O(nlogn)。
堆排序的特点是:在排序过程中,将排序数组看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲节点和孩子节点之间的内在关系,在当前无序区中选择关键字最大(或最小) 的记录。
堆排序基本思想:
1.将要排序的数组创建为一个大根堆。大根堆的堆顶元素就是这个堆中最大的元素。
2.将大根堆的堆顶元素和无序区最后一个元素交换,并将无序区最后一个位置例入有序区,然后将新的无序区调整为大根堆。重复操作,无序区在递减,有序区在递增。
完全二叉树的基本性质:
数组中有n个元素,i是节点,1 <= i <= n/2就是说数组的后一半元素都是叶子节点。
i的父节点位置:i/2
i左子节点位置:i*2
i右子节点位置:i*2 + 1
length[A]是数组中的元素个数,heap-size[A]是存放在A中的堆的元素个数
下面我是按照算法导论中给出的算法,利用c++实现了堆排序,调试通过。
#include <iostream>
using namespace std;
int data[10]={71,18,151,138,160 ,63 ,174, 169 ,79 ,78 };
void max_heapify(int data[],int i,int heapsize)//以某个节点为根节点的子树进行调整,调整为大顶堆
{
int l=2*i+1;
int r=2*i+2;
int largest=i;
if(l<heapsize&&data[l]>data[i])
{
largest=l;
}
if(r<heapsize&&data[r]>data[largest])
{
largest=r;
}
if(largest!=i)
{
int temp=data[largest];
data[largest]=data[i];
data[i]=temp;
max_heapify(data,largest,heapsize);
}
}
void bulid_max_heap(int data[],int heapsize)//建堆的过程,通过自底向上地调用max_heapify来将一个数组data【1……n】变成一个大顶堆,
{ //只需要对除了叶子节点以外的节点进行调整
for(int i=heapsize/2-1;i>=0;i--)
max_heapify(data,i,heapsize);
}
void heap_sort(int data[],int heapsize)//堆排序算法实现主体:先用bulid_max_heap将输入数组构造成大顶堆,
{ //然后将data【0】和堆的最后一个元数交换,继续进行调整。
bulid_max_heap(data,heapsize);
for(int i=heapsize-1;i>0;i--)
{
int t=data[0];
data[0]=data[i];
data[i]=t;
max_heapify(data,0,i);
}
}
int main()
{
cout<<"堆排序算法实现"<<endl;
cout<<"排序之前的数据:";
for(int i=0;i<10;i++)
cout<<data[i]<<" ";
cout<<endl;
heap_sort(data,10);
cout<<"排序之后的数据:";
for(i=0;i<10;i++)
cout<<data[i]<<" ";
cout<<endl;
return 0;
}