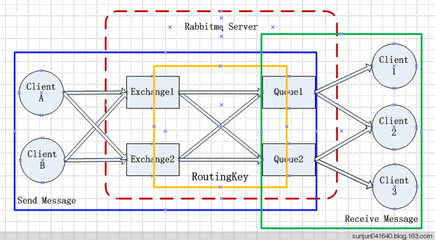
可靠的消息传输为什么一定要用RabbitMQ呢?直接用TCP,HTTP不OK?在回答这个问题时,我比较模糊。应该说这个应用的范围不同吧,TCP协议支持在IP之间进行消息传输,而RabbitMQ是根据关键字进行消息的分配和传输。TCP可以将消息从192.168.1.2传输到192.168.1.3。但是它不能将消息根据关键字进行传输吧,比如,给定一个关键字’key‘,你知道要将消息传输到哪吗?呵呵,RabbitMQ知道。
怎么根据关键字发送消息呢?这个嘛!理解比较简单,但介绍起来有点长。要理解这个发送机制,首先要对RabbitMQ的几个定义搞清楚:1Server,要利用RabbitMQ进行消息传输,那么就得有一个运行的RabbitMQ服务,我们可以称为Server2Producer,既然是传输消息,那得有一个消息的发送者,这里我们成为生产者(Producer)3 Consumer,消息的接收者,这里称为消息的消费这(Consumer)4 Exchange,在生产者将消息发出后,消息往哪走呢?这个得由Exchange来决定,可以将它看作一个交换机,它根据消息自带的特征信息(这里指的是routing_key),进行发送。发给谁呢?不是接收者,是下面的Queue。5Queue,一个Exchange可以对应多个Queue,每个Queue都会在定义时,声明自己要接收消息的特征信息(routing_key)。Exchange根据Queue和消息的routing_key的匹配情况进行发送。消息到达Queue后,Consumer就可以将消息从Queue取出了。 一个Server可以声明n多Exchange,一个Exchange可以对应n多Queue。Exchange和Queue都是存在Server内部的。简化点,可以理解为一个Producer与一个Exchange绑定,Producer将消息交给Exchange,Exchange负责发送消息。一个Consumer与一个Queue绑定,当Queue中有消息时,直接取就行了,管它怎么来的。而消息在Exchange在Queue之间的怎么传递,是由RabbitMQ负责的。我们只需要将消息交给Exchange,然后在Queue中取就行了。(当然还要多点步骤:声明消息和Queue的特征信息,将Queue与Exchange进行关联) 用一个来自官网的图片说明下:P: Producer, X: Exchange, amq:Queue, C: Consumer
在消息的传输机制上理解,较为简单。但在源码级别上,进行使用要为复杂。这个我个人要归功于RabbitMQ客户端的几种封装,让我是分不清东南西北。下面是官网上列举的六个应用实例,有易到难,比较容易理解。
1直接发送模式不声明Exchange,即采用默认的Exchange。默认的Exchange可以根据routing_key将消息直接发送给特定Queue。注意:1)这种匹配是消息的routing_key与Queue的名子直接进行匹配,而不是与Queue的routing_key。2)消息并不能直接发送给queue,这里是经过一个名为''的Exchange进行发送的。Producer.py
#!/usr/bin/env pythonConsumer.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))
channel = connection.channel()
#这里要对queue进行声明,已确定Queue存在,如果不存在则创建名为‘hello'的queue。
#否则消息发送时,queue不存在,消息会被直接丢弃
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='', routing_key='hello', body='Hello World!')
print " [x] Sent 'Hello World!'"
connection.close()
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
print ' [*] Waiting for messages. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
channel.basic_consume(callback, queue='hello', no_ack=True)
channel.start_consuming()
2工作列队模式该模型适用于分发资源密集型的任务。假设一下你需要进行10次计算圆周率的操作,每次计算到小数点后n位,每次耗时1一个小时(这只是一个假设,一般没有比要进行10重复操作的。现在就当作你真的有这个必要)。如果只用一台机器计算,需要十个小时。但如果我们将这十个任务分发给十台进行计算,那么只需一个小时。下面的模型就是适用于这种分发任务的。
采用这种模式,列队消息以轮询(round_robin)的方式将消息平均的发给所有与Queue关联的Consumer,一般情况下,每个Consumer都平均的分摊任务。注意:1)在目前的情况下,消息一旦被Consumer取出,就立即从列队中消除。这样当woker执行到任务中途失败时,该任务的信息也丢失了,不能重新开始。2) RabbitMQ提供一种消息认证机制(messageacknowledgments),只有当Consumer返回一个ack时,它才会将消息从列队中删除。如果当Consumer断开连接时,依然没有收到ack,那么它就会重新分发给消息。3)RabbitMQ不允许以新的属性来重新定义Queue,所以这里我们需要给Queue换个新名子Producer.py
#!/usr/bin/env pythonConsumer.py
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))
channel = connection.channel()
#Queue声明持久化
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='', routing_key='task_queue', body=message,
properties=pika.BasicProperties( delivery_mode = 2, # 消息声明持久化))
print " [x] Sent %r" % (message,)
connection.close()
#!/usr/bin/env python3广播(fanout)模型前面两种模型,每条消息只能被一个Consumer获取。原因在于:使用默认的Exchange,它只能将每条消息发给一个或零个Queue中。这里我们将使用一种类型为fanout的Exchange,它可以将消息发送给每一个于它关联的Queue,这样每个Consumer都可以获取相同的消息。Producer.py
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))
channel = connection.channel()
#Queue声明持久化
channel.queue_declare(queue='task_queue', durable=True)
print ' [*] Waiting for messages. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
#返回消息认证
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback, queue='task_queue')
channel.start_consuming()
#!/usr/bin/env pythonConsumer.py
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))
channel = connection.channel()
#定义一个类型为fanout的Exchange
channel.exchange_declare(exchange='logs', type='fanout')
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs', routing_key='', body=message)
print " [x] Sent %r" % (message,)
connection.close()
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', type='fanout')
#由于此时Exchange将消息发给所有的Queue,所以Queue无需命名,
#此处没有给queue指定名称,MQ会给它产生一个随机名子。
#参数exclusive=True指定,当consumer断开连接时,立即删除相应的queue
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='logs', queue=queue_name)
print ' [*] Waiting for logs. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] %r" % (body,)
channel.basic_consume(callback, queue=queue_name, no_ack=True)
channel.start_consuming()
4direct模型到目前为止,Consumer只能被动的随机接收一部分消息,或者接收全部,不能自主选择接收哪一部分消息。该消息路由模型,可以使得Consumer指定它想要接收到消息。
将Exchange声明为direct类型:
channel.exchange_declare(exchange='direct_logs', type='direct')将Queue与Exchange绑定,注意此处queue与Exchange绑定时,指定了一个参数routing_key。如上面两图所示,一个queue可以以多个routing_key与Exchange进行绑定,多个不同的Queue可以以相同routing_key与同一个Exchange进行绑定。遗留一个问题,一个Queue可不可以与多个Exchange进行绑定呢?:
channel.queue_bind(exchange=exchange_name, queue=queue_name, routing_key='black')发送消息:
channel.basic_publish(exchange='direct_logs', routing_key=severity, body=message)在发送消息时,也会指定一个routing_key。当Exchange在决定将消息发给哪几个Queue时,它会将该routing_key与Queue绑定时指定的routing_key进行匹配,相同的Queue则可接收消息。Producer.py
#!/usr/bin/env pythonConsumer.py
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs', type='direct')
severity = sys.argv[1]if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs', routing_key=severity, body=message)
print " [x] Sent %r:%r" % (severity, message)
connection.close()
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs', type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
print >> sys.stderr, "Usage: %s [info] [warning] [error]" % (sys.argv[0],)
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity)
print ' [*] Waiting for logs. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] %r:%r" % (method.routing_key, body,)
channel.basic_consume(callback, queue=queue_name, no_ack=True)
channel.start_consuming()
5Topic模型direct模型是不是已经很好用、很灵活了?不,它的灵活度还不够。看它在routing_key进行匹配时,只能将两个完全相同的routing_key进行匹配,这个不够好,要是能用正则表达式进行匹配,那就完美了。Topic模型,虽然没有实现用正则表达式进行匹配,但是它进步了一小步。实现了对任意的单词进行匹配:
Producer.py
#!/usr/bin/env pythonConsumer.py
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs', type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs', routing_key=routing_key, body=message)
print " [x] Sent %r:%r" % (routing_key, message)
connection.close()
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs', type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
print >> sys.stderr, "Usage: %s [binding_key]..." % (sys.argv[0],)
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key)
print ' [*] Waiting for logs. To exit press CTRL+C'
def callback(ch, method, properties, body):
print " [x] %r:%r" % (method.routing_key, body,)
channel.basic_consume(callback, queue=queue_name, no_ack=True)
channel.start_consuming()
6远程调用模型(RPC)这个是对RabbitMQ消息传输的实际应用,在Openstack中,各个组件间的调用就是通过RabbitMQ实现的,这样是我为什么学习RabbitMQ的原因了。个人猜想,Client端执行远程调用(RPCCALL),通过一个Queue将函数名、传参、已经用于传输返回结果的临时声明的Queue(这个Queue在声明时,无需指定名子,由RabbitMQ自动分配,这样还可以避免命名冲突),Server端接收到消息后,调用相应的函数进行处理,并将结果通过默认Exchange传给临时Queue,这样就完成了一个远程调用。但是这个猜想有问题:每进行一次RPCCALL就要声明一个临时Queue。这个有点浪费。有多浪费我也不知道,没测试过。我们可以为每个Client指定一个用于返回结果的Queue,这样就不用每次声明了。每次RPCCALL时,绑定一个correlation_id,这样使得返回的结果不会混乱。注意:在返回结果的Queue中可能存在脏数据,比如,Server在将结果传输到Queue后,还没来得及返回消息确认就挂了。那么先前发的调用消息就不会消除,在Server下次启动时会再次执行,并再次返回结果。这就有了脏数据。所以,面对Queue里的脏数据,我们只需忽略就行了。Server.py
#!/usr/bin/env pythonClient.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def on_request(ch, method, props, body):
n = int(body)
print " [.] fib(%s)" % (n,)
response = fib(n)
ch.basic_publish(exchange='', routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue')
print " [x] Awaiting RPC requests"
channel.start_consuming()
#!/usr/bin/env python
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))
self.channel = self.connection.channel()
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(self.on_response, no_ack=True, queue=self.callback_queue)
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='', routing_key='rpc_queue', properties=pika.BasicProperties( reply_to = self.callback_queue, correlation_id = self.corr_id, ), body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response)
fibonacci_rpc = Fibonacc iRpcClient()
print " [x] Requesting fib(30)"
response = fibonacci_rpc.call(30)
print " [.] Got %r" % (response,)